Searching through error data efficiently is critical for developers using monitoring tools. At Rollbar, we recently completed a significant overhaul of our Item Search backend. The previous system faced performance limitations and constraints on search capabilities. This post details the technical challenges, the architectural changes we implemented, and the resulting performance gains.
The Starting Point: Limitations of the Existing Architecture
Our previous item search relied heavily on our primary MySQL database for most filtering and sorting operations, with Elasticsearch used for fulltext search on item titles. This architecture presented several challenges:
- Performance Bottlenecks: Complex MySQL queries combining item and occurrence filters often struggled. Occurrence data, being voluminous, is difficult to index effectively in a traditional RDBMS for arbitrary filtering. Many searches, especially those involving occurrence attributes or non-default time ranges, exceeded the 60-second timeout threshold in our database.
- Impact of Core Features (like Merging): Rollbar allows merging similar items together. Rollbar's merge operation is designed to be O(1), independent of occurrence count. Supporting this fast merge while correctly associating occurrences with their current parent item required complex logic within MySQL, involving self-joins on the item table. This made the queries difficult for MySQL to optimize, especially when combined with other filters.
- Data Propagation Delays: Changes in item relationships (like merges) were propagated from MySQL to our analytics backend (used for some auxiliary data lookups) via a CDC pipeline (Debezium) feeding a Clickhouse dictionary. This dictionary refreshed on a schedule, about every 20 minutes. This meant merges performed by users wouldn't be reflected in certain views or potentially in search refinement for a considerable time.
- Limited Search Capabilities: Filtering on many occurrence-level fields (like ip_address, server_host, code_version, custom data, request headers) was either impossible or prohibitively slow due to indexing limitations or query complexity.
- Data Accuracy Issues: Sorting based on occurrence data aggregated in the item table didn't always work as expected, particularly for custom time ranges. Searches could yield unexpected results when combining time ranges with occurrence attribute filters.
The New Architecture: Specialization and Separation
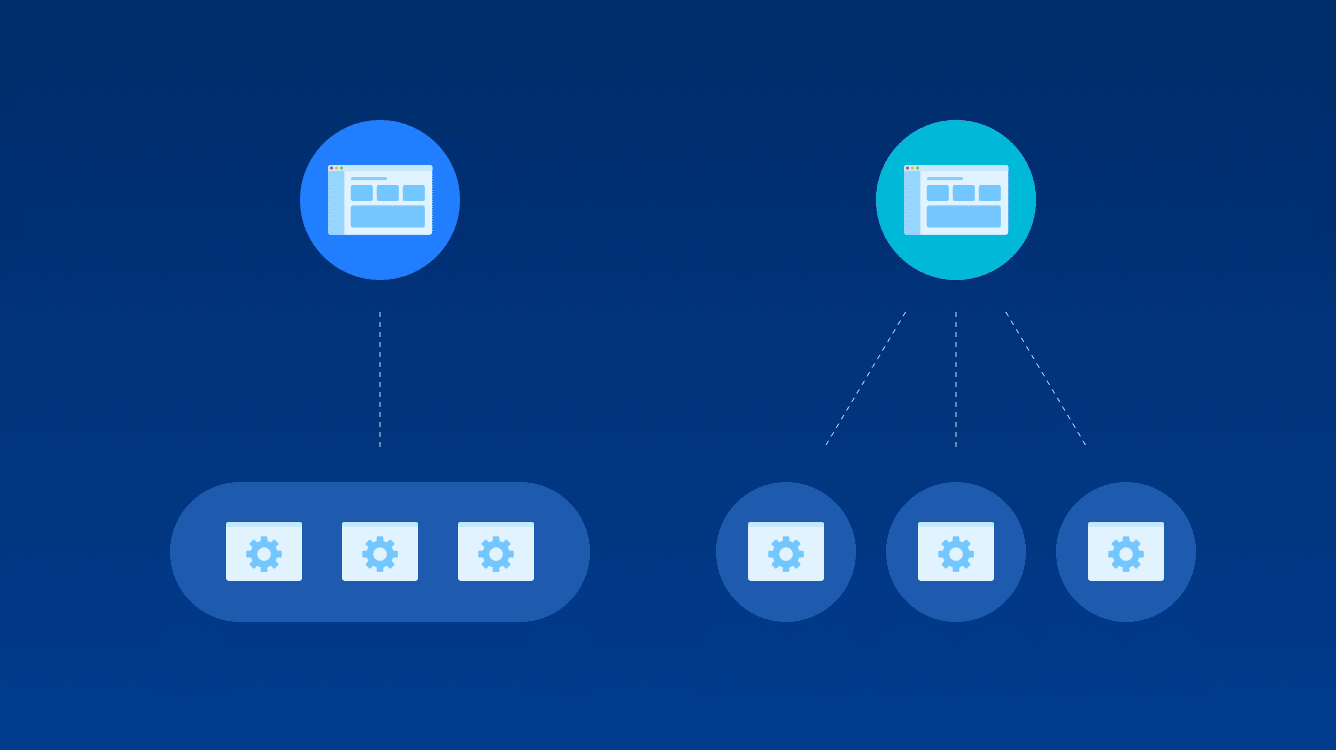
The core principle behind the new architecture is to use the right tool for each part of the job, splitting the query execution across specialized data stores:
- MySQL: Continues to handle item-level filtering (e.g., status, assignment, framework, level). These attributes are relatively static per item and well-suited for MySQL's indexing. We focused on optimizing queries and indexes here, while acknowledging the inherent complexity needed to support features like merging during the initial item selection phase.
- Clickhouse: Now handles all occurrence-level filtering and sorting. Clickhouse's columnar storage, sparse primary key indexes, and parallel query execution are highly effective for scanning and aggregating large volumes of occurrence data.
- Elasticsearch: Remains responsible for item title search.
Queries now execute sequentially. An initial query might hit the MySQL database and/or Elasticsearch to get a set of candidate item IDs based on item filters and title. This list of IDs (if below a threshold size) is then passed to our Clickhouse cluster to perform filtering based on occurrence data and time ranges, and to handle sorting accurately based on potentially billions of occurrences. In the event that the list of IDs exceeds the threshold, we reverse the order: we search Clickhouse first, then filter the results using MySQL, looping until we exhaust the search or return the requested number of results.

Deep Dive 1: Leveraging Clickhouse for Occurrence Data
Clickhouse's MergeTree engine family provides significant advantages for occurrence data:
- Columnar Storage: Efficient scans of specific columns needed for filtering.
- Sparse Primary Key Index: Small index size, fast identification of relevant data blocks (granules). Our primary key is (project_id, environment, item_id, timestamp).
- Parallel Scans: Scans relevant granules concurrently across many threads.
Queries filtering on occurrence properties that previously timed out after 60+ seconds in MySQL often complete in less than 1 second in Clickhouse. This architecture also enabled us to expose many more occurrence fields for filtering, leveraging Clickhouse's native functions for string matching and JSON processing.
Deep Dive 2: Real-Time Merge Sync with Clickhouse
The 20-minute delay in propagating merge data to Clickhouse was unacceptable in the new system, where Clickhouse plays a central role in filtering. A user merging items needed to see the result reflected in subsequent searches almost immediately.
The Solution: We implemented a direct, near-real-time synchronization mechanism:
- Dedicated Clickhouse Table: A new ReplicatedReplacingMergeTree table was created in Clickhouse specifically to store the mapping between an item ID and its current group (parent) item ID. This table only stores id, group_item_id, a deleted flag, and a row_version. It's very small and efficient.
- Direct Application Updates: When a user performs a merge or unmerge in the Rollbar application, the application code now directly writes the updated mapping (or a deletion marker) to this new Clickhouse table, bypassing the slower CDC pipeline for this specific data.
- Targeted Dictionary: A small, in-memory Clickhouse dictionary (dict_mox_grouped_item) sources its data only from this dedicated merge mapping table (using a view with FINAL to get the latest state).
- On-Demand Refresh: After writing the update to the Clickhouse table, the application code immediately triggers a refresh of this specific dictionary using SYSTEM RELOAD DICTIONARY dict_mox_grouped_item.
- UI Synchronization: The Rollbar UI waits for confirmation that the dictionary refresh is complete (typically just a few seconds) before updating the view to show the results of the merge.
This ensures that subsequent queries hitting Clickhouse use the absolutely latest merge mapping data, providing a near-seamless user experience for the merge feature within search.
Deep Dive 3: MySQL Query Optimization
The last hurdle was fetching item details after initial filtering, exacerbated by the need to determine the correct "controlling" item ID after merges. One specific query responsible for fetching item data for display could take over 5 seconds.
Before Optimization:
-- Simplified Example Structure - Showing Merge Logic Impact
SELECT
IF(i.status=4, group_item.some_column, i.some_column) AS some_column, -- Use parent data if merged
-- ... many similar IF conditions ...
IF(i.status=4, group_item.id, i.id) AS controlling_id -- Determine controlling ID
FROM item i
LEFT JOIN item group_item ON i.group_item_id = group_item.id -- Self join for merge info
LEFT JOIN ... -- Other joins
WHERE
i.project_id IN (...) AND
-- Filters might apply to either original or group item based on status
IF(i.status=4, group_item.status, i.status) IN (...) AND
IF(i.status=4, group_item.level, i.level) IN (...) AND
IF(i.status=4, group_item.id, i.id) IN (...) -- Filter on controlling IDs
GROUP BY controlling_id;
-- Example Performance: 51 rows in set (5.68 sec)The self-join and extensive IF() conditions, necessary to handle the merged item state correctly, prevented MySQL from efficiently using indexes.
After Optimization:
Once the initial set of controlling item IDs has been determined, fetching the final page of data can be much simpler. Because at the final phase we know the actual item ids that are being returned, the merge information is not needed and therefore the self-join can be removed. This makes the query much simpler and orders of magnitude more performant.
-- Simplified Example Structure (Second Query)
SELECT
i.id AS id,
i.project_id AS project_id,
-- ... direct column selection ...
i.title_lock AS title_lock
FROM item i
LEFT JOIN item_snooze_rule isr ON isr.item_id IN (i.id) -- Simpler joins only if needed
LEFT JOIN item_assigned_team iat ON iat.item_id IN (i.id)
WHERE
i.id IN (...); -- Direct filter on known controlling IDs for the final page
-- Example Performance: 51 rows in set (0.00 sec)This optimization reduced this specific query's time from ~5.68 seconds to less than 0.01 seconds. It shows how isolating different concerns (item state vs. occurrence filtering) allows for more targeted optimizations.
The Results: Measurable Improvements
This initiative delivered substantial improvements:
- Speed: Overall search performance is typically 10x to 20x faster. Queries that previously timed out (>60s) now consistently return in roughly 1-2 seconds. Merging items now reflects in search results within seconds, not 20 minutes.
- Capability: Dozens of new occurrence fields are available for filtering and text matching. Custom key/value data is searchable.
- Accuracy: Time range filtering and sorting are now accurate, reflecting actual occurrences. Total occurrence counts and unique IP counts are accurate.
- Reliability: Query timeouts are drastically reduced.
Here's a snapshot from our performance comparison tests:

Conclusion
Overhauling a core feature like search is a significant undertaking. By analyzing bottlenecks and applying specialized data stores (optimized MySQL for item data state, Clickhouse for occurrence data with real-time merge mappings), we dramatically improved search speed, capability, accuracy, and responsiveness for core workflows. These updates not only provide a much better user experience but also establish a more robust and scalable foundation for future enhancements to Rollbar's capabilities.