Product
FEATURES
Discover
Prioritize
Resolve
Automate
Improve
LANGUAGES/FRAMEWORKS
INTEGRATIONS
SECURITY
Compliance
PRODUCT UPDATES
Pricing
Docs
Developer
Documentation
Roadmap
System Status
Resources
Blog
Guides
Videos
Rollbar Academy
Events
Live Demo
Solutions
TEAMS
Software Development
Engineering Management
QA/Testing
Platform/Ops
Customer Support
Software Agency
Use Cases
Low-Risk Release
Production Code Quality
DevOps Bridge
Customer Support
Effective Testing & QA
Customers
Enterprise
Log in
Try free
Log in
Try free
Rollbar Blog
Product
See all posts
Introducing Overage Budgets
Read more
Introducing IP Safelist for our API access
Read more
Pay directly from your bank account
Read more
Removing Support for TLS 1.0 and 1.1 Protocols
Read more
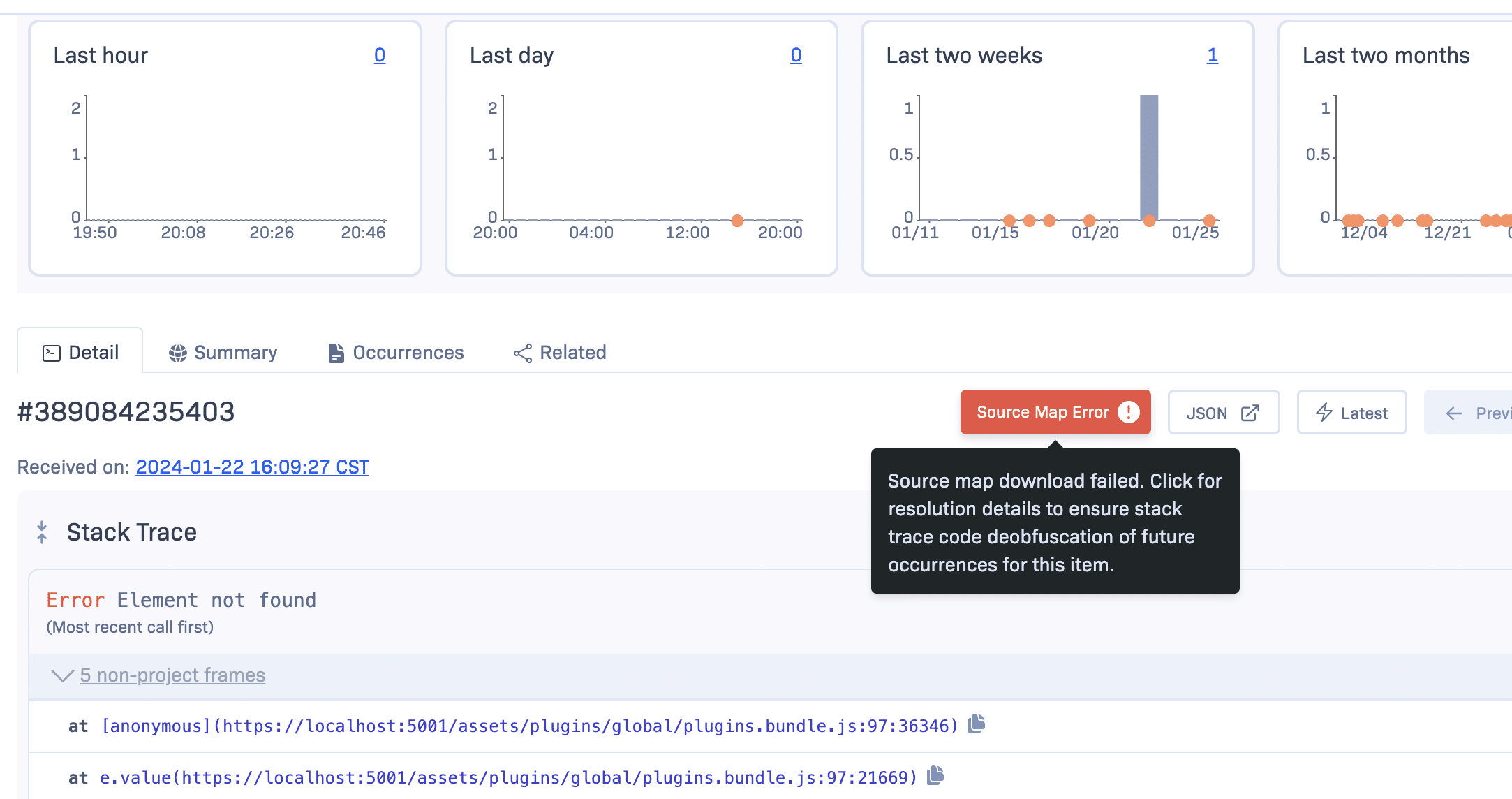
New Source Map Error Workflow
Read more
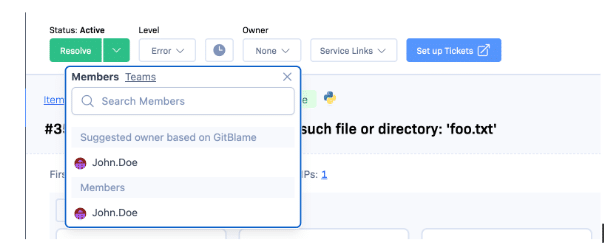
Auto-suggest item owner based on Git Blame data
Read more
Company
See all posts
Warmup Inbox's Story with Rollbar
Read more
Sergey's story with Rollbar
Read more
Robin's story with Rollbar
Read more
Benoit's story with Rollbar
Read more
Ibrahim's story with Rollbar
Read more
Adam's story with Rollbar
Read more
Topics
See all posts
Sentry, But Better? 6 Sentry Alternatives to Keep Your Code Error-Free
Read more
5 Best Error Monitoring Tools to Use in 2024
Read more
Angular vs. React: Which is Better, and When?
Read more
Rollbar Alternatives: Compare Before You Commit
Read more
Next.js or Vite.js: Which Framework is Better, and When?
Read more
Next.js or Remix: Which Framework is Better, and When?
Read more
Tutorials
See all posts
How to Fix the "document is not defined" Error in JavaScript
Read more
Logging Levels in Python are Unnecessary - Just Log Everything
Read more
How to Fix The Illegal
State
Exception in Java
Read more
How to Fix "Illegal Start of Expression" in Java
Read more
How to Handle Checked & Unchecked Exceptions in Java
Read more
What is “except Exception as e” in Python?
Read more
Company
behind-the-scenes
company growth
continuous-delivery
customer-stories
Customer Support
error-monitoring
Events
funding
postmortem
remote-work
team
Product
access-management
API
APM
behind-the-scenes
continuous-delivery
continuous-deployment
debug
dotnet
error-feed
error-monitoring
grouping
integrations
macOS
java
JavaScript
monitor
onboarding
PHP
ruby
SDK
security
Slack
stacktrace
team
triage
Topics
APM
behind-the-scenes
build vs buy
business-impact
continuous-delivery
debug
dora-metrics
error-handling
error-monitoring
frameworks
JavaScript
kafka
Top Errors
Tutorials
angular
AWS-lambda
behind-the-scenes
debug
dotnet
frameworks
golang
integrations
java
JavaScript
laravel
mobile
monitor
nodejs
PHP
Python
ruby
SDK
Selenium
source-maps
sql
vuejs