In the first post of this series, we looked at the state of your organization, how to tell if Microservices are right for you, and wrapped up with a few challenges this architecture brings to the table.
In this article, we will look at organizational changes that will help you adopt a Microservice architecture. Additionally, we will touch on topics like how to bring change to your organization, how to embrace the primacy effect, and why you should embrace cross-functional teams. We'll also discuss several ways to change how you develop applications in a Microservice architecture. These items include topics like streamlining your build - optimizing how you build your Monolith, detangling your dependencies - setting up your Monolith for Microservices and optimizing your local development environment.
Organizational Changes
Here are best practices to prepare your organization to transition from a Monolithic codebase to a Microservices architecture.
Establish Goals
You should establish clear, measurable goals for your first projects. Everyone involved in the process, from the executive team down through the cross-functional team, should understand and agree on the initial goals. Since this will be a completely new and unfamiliar process, failure should be treated as a learning experience rather than punishable. Use these inaugural teams to flesh out your automation, streamline your development process, and experiment with different ways to build Microservices.
Consider how people in your organization will be affected by the primacy effect, which is a cognitive bias that results in recalling what you first encounter better than the information you learn later. Given how powerful the primacy effect is, you will want to manage each team's exposure to your new strategy. Having a clearly-defined plan, support system, and dedicated resources to ensure each team is successful will help make the transition as smooth as possible. This is a great opportunity to create new workflows for your team.
Measure Everything
If your Monolith has been around for years, then you likely don't have detailed metrics on how various components communicate. Business-oriented metrics may not be part of your team's Key Performance Indicators (KPIs). Maybe your teams don't even have KPIs.
For many years, measurements like KPIs have been used by marketing and finance teams, however, KPIs play a critical role in managing a Microservice architecture. Peter Drucker, inventor of modern business management, is credited with the concept "If you can't measure it, you can't improve it."
Want to increase your deployment frequency? Measure it. Want to decrease deployment time? Measure how long it takes to deploy your software. Start by identifying one aspect of your development process that you want to improve. Devise a metric to track this process. Then, work to improve the KPI each week, increasing or decreasing the indicator as appropriate.
Start Small
The desire to "boil the ocean", or a call for "all hands on deck" is a common way to tackle a new concept. However, there are many uncertainties during the initial stages of this process. Focusing on several teams that will build services off to the side of your Monolith will ensure your rollout goes smoothly. An organization-wide transformation is something very few companies have accomplished. By starting small, you are stacking the deck in your favor of a long-term, successful rollout.
Assemble Cross-functional Teams
From day one, you will need cross-functional teams comprised of developers/QA, operations, and business owners. Microservices require a different team structure. Instead of silos collaborating, create teams that can design, build, deploy, and support a service without the need for any other team or approval process. Cross-functional teams should own their service from inception to retirement.
Don't Depend on the Monolith
Your initial Microservices shouldn't depend on your Monolith at the code level. It's better to build services that sit off to the side of your Monolith and have limited exposure to your customers. This way, your teams can establish a new way of building software in your organization. Be aware, if these projects rely on the Monolith, they will also be tied to its release cycle.
Stop Adding Features to Your Monolith
Stop adding new services and features to your Monolith. For the first few months, as your initial teams build out their microservices, it should be business as usual. Once you have some useful implementation patterns and have tailored the process to your organization, you'll want to create a plan for breaking apart the Monolith.
At this point, carefully consider any changes you make to your Monolith. If possible, add new features as Microservices that are decoupled from your Monolith. See the Anti-corruption layer and change-data capture below for ways to augment your Monolith.
Application Changes
Here are 10 specific ways to improve your Microservice architecture and streamline your transformation from a Monolithic architecture. Some of these items are more applicable at the beginning of your transformation and others are useful once you have a few services in production.
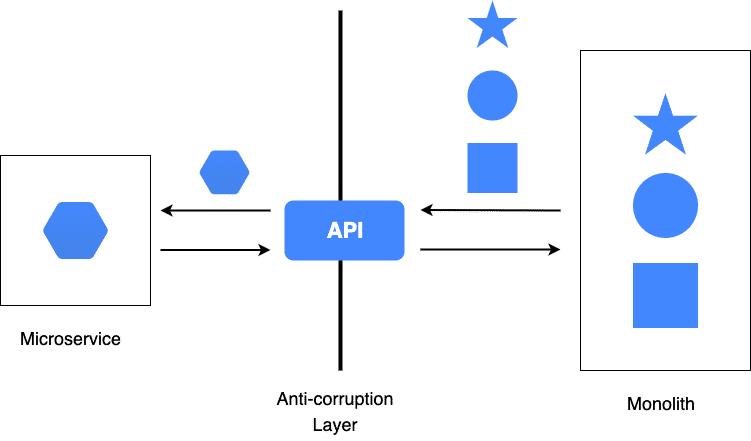
Implement an Anti-corruption Layer
Your first few Microservices shouldn't rely on your Monolith; otherwise, your new service is bound to the Monolith release cadence. At some point, however, your Microservices will need to interact with your Monolith. To keep the coupling as loose as possible and to keep the Monolith domain model out of your Microservice, consider adding an Anti-corruption layer This layer will translate the Monolith API and will result in structures and APIs that are compatible with your Microservice. This layer will isolate your Microservice from the Monolith while giving you access to existing behavior. This pattern was first introduced by Eric Evans in the book Domain-Driven Design.
Streamline Your Build
Most Monoliths have existed for years. If your Monolith is a Java project using Maven, you may have dozens to hundreds of modules making up your service. Other languages and build systems have similar mechanisms for modularizing your code. The bottom line, your build process may have not been touched in years.
As a first step, streamline your build. Remove magic variables, special environment variables or other settings that are required to build and package your system. During this process, you'll get to know your system better than ever before.
Detangle Your Dependencies
Once you've streamlined your build, look at the dependencies between the modules of your Monolith. Maintaining a clear separation of concerns between modules in a Monolith is difficult to do. Your IDE makes it easy to refactor methods and move code around.
Before you decompose your Monolith you'll want to clean up inter-module dependencies. One way to approach this is to put any cross-module dependency into a "common" module. Once you've moved the dependencies to common you'll have a better idea of what's being used across your modules. Then, you can decide on the best strategy for refactoring or moving these common classes/functions.
Optimize for Local Dev
Ensure your development teams have all the tools and software necessary to rapidly build, test, and debug the services they are building to increase their velocity. Rather than using cloud-side infrastructure to develop locally, consider frameworks like Localstack. Embrace tools like Docker for local development. This enables your dev team to spin up databases, message queues, and caching layers quickly and easily.
If your operations team is building custom services, make sure there is a Docker container available so your development teams can understand the customization before they get to the build pipeline, or worse, a test/stage/production environment.
Use Trunk-Based Development
Embrace trunk-based development. According to the 2017 State of DevOps Report, "high performers have the shortest branch lifetimes." This is a version control branching model that encourages developers to collaborate on trunk (master in Git). Instead of creating long-lived branches, create short-lived branches (measured in hours instead of days or weeks) that are merged back to trunk every 24 hours.
Establishing new processes around merging code to master, using branch protection to ensure a pull request (PR) is created before code is merged to master. Additionally, defining a code review process for each PR will prepare teams for continuous deployment. Couple this approach with a Continuous Delivery pipeline and you'll be positioned to move quickly and safely into production.
Support Parallel Development
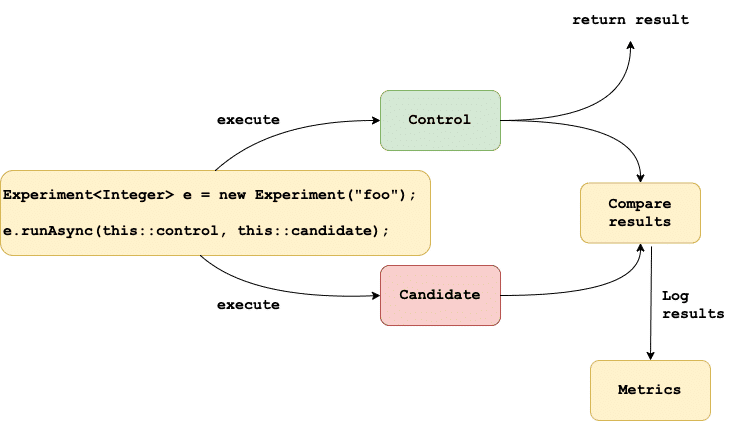
How can you test a new implementation of an existing algorithm without negatively impacting your existing users? Is it possible to test your new code in production before its feature complete? Can your rewrite of an existing feature handle production load?
To answer these questions and many others, consider using GitHub Scientist (written in Ruby). GitHub's Scientist enables you to run multiple implementations or experiments in parallel and collect metrics for each implementation. You can use the metrics to decide when the new implementation should replace the existing implementation, when to terminate the experiment or when to skip the new code path entirely.
Not using Ruby? See the GitHub project for ports to other programming languages.
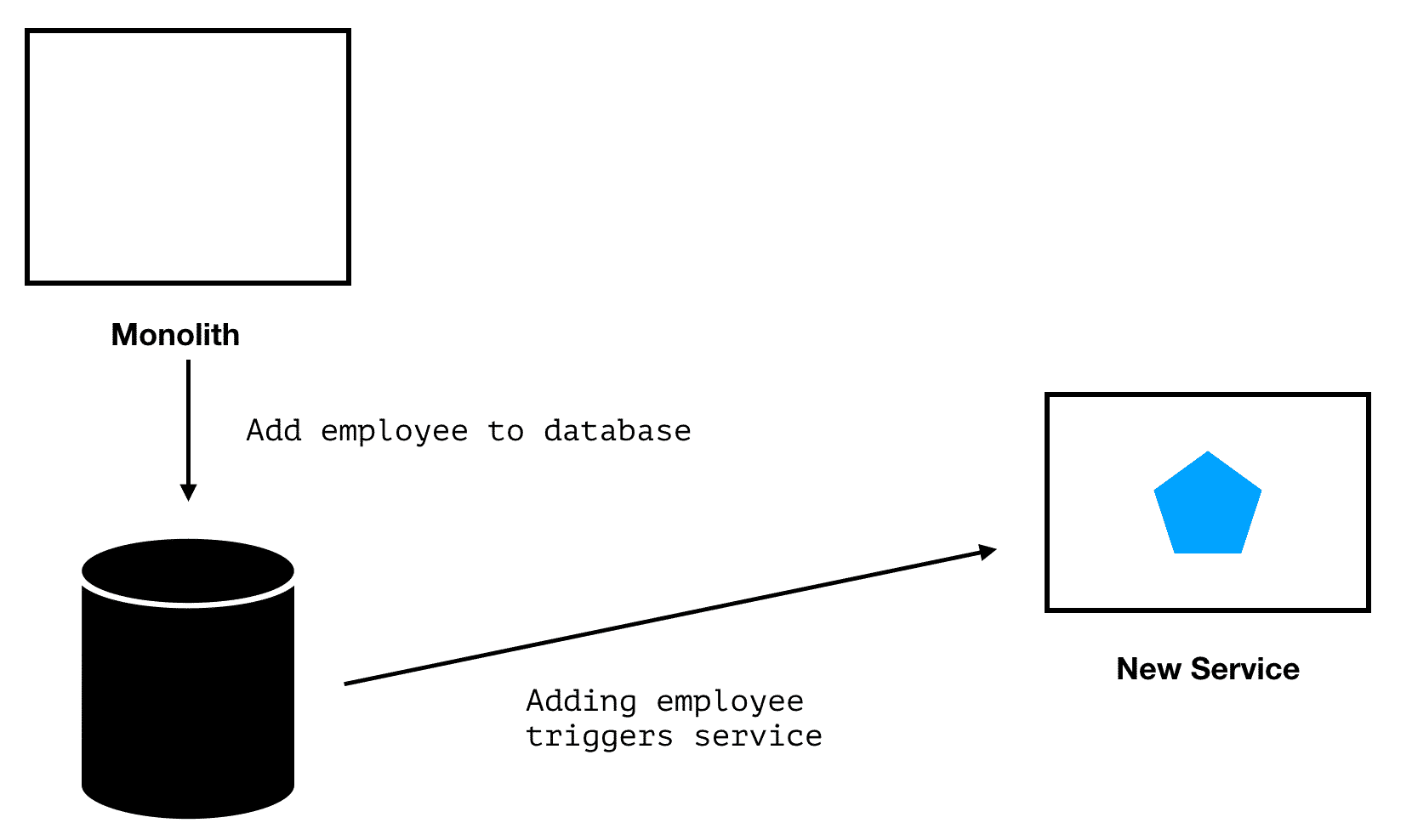
Leverage Change Data Capture
There are several ways to add new behaviors to your Monolith without updating its codebase. One option is to use the Change Data Capture (CDC) design pattern. "Change data capture is the process of capturing changes made at the data source" and sending these changes to other systems. To illustrate this process, imagine you have a Human Resources system and you want to add a "new hire" process. You can use CDC to identify when a new employee is added to your database and then trigger your new Microservice. A similar pattern is Command Query Responsibility Segregation. With CQRS the source systems send out events with the data that has changed and other systems listen for these events and take appropriate action. See Microservices.io for a detailed description of this pattern.
Adopt Infrastructure as Code Processes
Infrastructure as Code (IaC) is defining your infrastructure in code, just like you would software. IaC enables you to use the same approach for infrastructure as you would use for software, specifically version control, peer reviews, testing, and deployment.
Adopting IaC early will enable you to create more uniform and consistent environments. Using a programmatic approach to provisioning and deploying infrastructure will also help you to view infrastructure as cattle instead of pets, which is easy to replace instead of continually managing and updating it. Developers may also use significant portions of your IaC for creating their own local development environments; this brings cloud services closer to their laptops.
Remove Undifferentiated Heavy Lifting
This applies to both operations and development. Werner Vogels, CTO at Amazon.com, coined the phrase "Undifferentiated heavy lifting" to describe the hard work dev and ops do that doesn't add value to your company mission. If every company needs the service or functionality, then it's undifferentiated work.
Before you embark on building your own solution or even enhancing an existing tool to meet your needs, look for other alternatives. Does your cloud provider already have a solution? Is there a paid version of the OSS project you are customizing that provides the features you want to implement? Be critical of any code you write that doesn't focus on your company's core mission.
Be Observable
Making Microservices "highly observable" is one of the seven Microservice principles outlined by Sam Newman in Building Microservices. As your system behavior moves from one codebase to many, and as your infrastructure becomes more dynamic, you'll need better insight into how services are performing. Since services often result in complex call chains, you need to be able to trace these calls across your system to debug problems.
By taking an early lead on building observability into your initial projects, you'll benefit from the primacy effect and establish patterns for future teams and services. Teach your team how to leverage tools like application performance monitoring (APM), distributed tracing, logging, and error monitoring in a Microservices environment.
For example, using a tool like Rollbar will give you visibility into error rates across your Microservices and provide contextual data to debug the problem including the request payload, local variables, deployment version, and more. This will help you to trace errors to their root cause even in complex and dynamic environments.
Conclusion
We presented you with several ways to prepare your organization for a successful transformation. Set your initial teams up for success, provide them with clear objectives, training, and the budget needed to bring Microservices into your environment.
We also looked at various ways to change how you build your applications. Optimize for better local development velocity by bringing cloud infrastructure closer to your laptop, remove undifferentiated heavy lifting, and teach your team how to improve observability of their code to solve problems faster.
If you haven't already, check out the first post in our series on the challenges of Microservices or learn about the differences between a monolithic architecture and microservices architecture.