Velocity, much like the pulse rate or oxygen level of an individual, is an important measure of health for your development team. A low velocity score for recent sprints limits your team's options for delivering value. Sustained failure to deliver to stakeholders can erode trust with those stakeholders quickly. But how do you know exactly what your velocity is and how you can improve it?
In this article, we'll share some best practices for improving the throughput of your development team and how to use velocity as a measure to ensure that throughput stays high.
The practices and ideas in this article come from the research of Dr. Nicole Forsgen and Jez Humble. Their research is shared in the 2018 book Accelerate and represents the distillation of over 23,000 survey responses over four years of annual DevOps surveys. Dr. Forsgren, VP of Research & Strategy at GitHub, has proved in her research that high performing IT organizations use the practices and techniques shared in this article.
First, let's look at exactly what we mean when we say velocity.
What Is Velocity and Why Does it Matter?
What Is Team Velocity?
Velocity is a capacity planning tool that was introduced in Agile methodologies like eXtreme Programming (XP) and Scrum. In both those methodologies, work is broken down into user stories, the team estimates how much effort each story will take to get done, and then uses this estimate to commit stories for that development iteration or sprint. Velocity is expressed in units that the team defines. The units may be anything. Common units are based on time (such as days or hours) or story points.
Agile luminary Martin Fowler defines velocity as "a statement of how much stuff a team (or a person if it's personal velocity) gets done in a time period." Fowler emphasizes that velocity allows a team to estimate how much work may be done in the future. For example, if the team delivered a consistent amount of work over the past three sprints, it's reasonable to anticipate that a team will deliver the same amount of work next time.
Why Does Team Velocity Matter?
Velocity helps your team predictably deliver work. If you're not tracking what you delivered to production last sprint, then you have no baseline to predict your capacity for the next sprint. Velocity can also surface issues with your team. A very low velocity clearly shows an issue needs addressed: perhaps there's serious test infrastructure issues or spiraling technical debt. A very high or inflated velocity score means your team is at risk of over-promising and under-delivering. Perhaps finished features have been piling up and the team is delivering many sprints' worth of work. Or the team is overestimating the work involved in stories. In all cases, to most effectively predict and manage the work to be delivered, it's important that your instruments for planning sprints are accurate.
Five Ways to Improve Team Velocity
Now, let's look at five ways your team can improve velocity and deliver more features, more predictably.
1. Always Do the Sprint Retrospectives
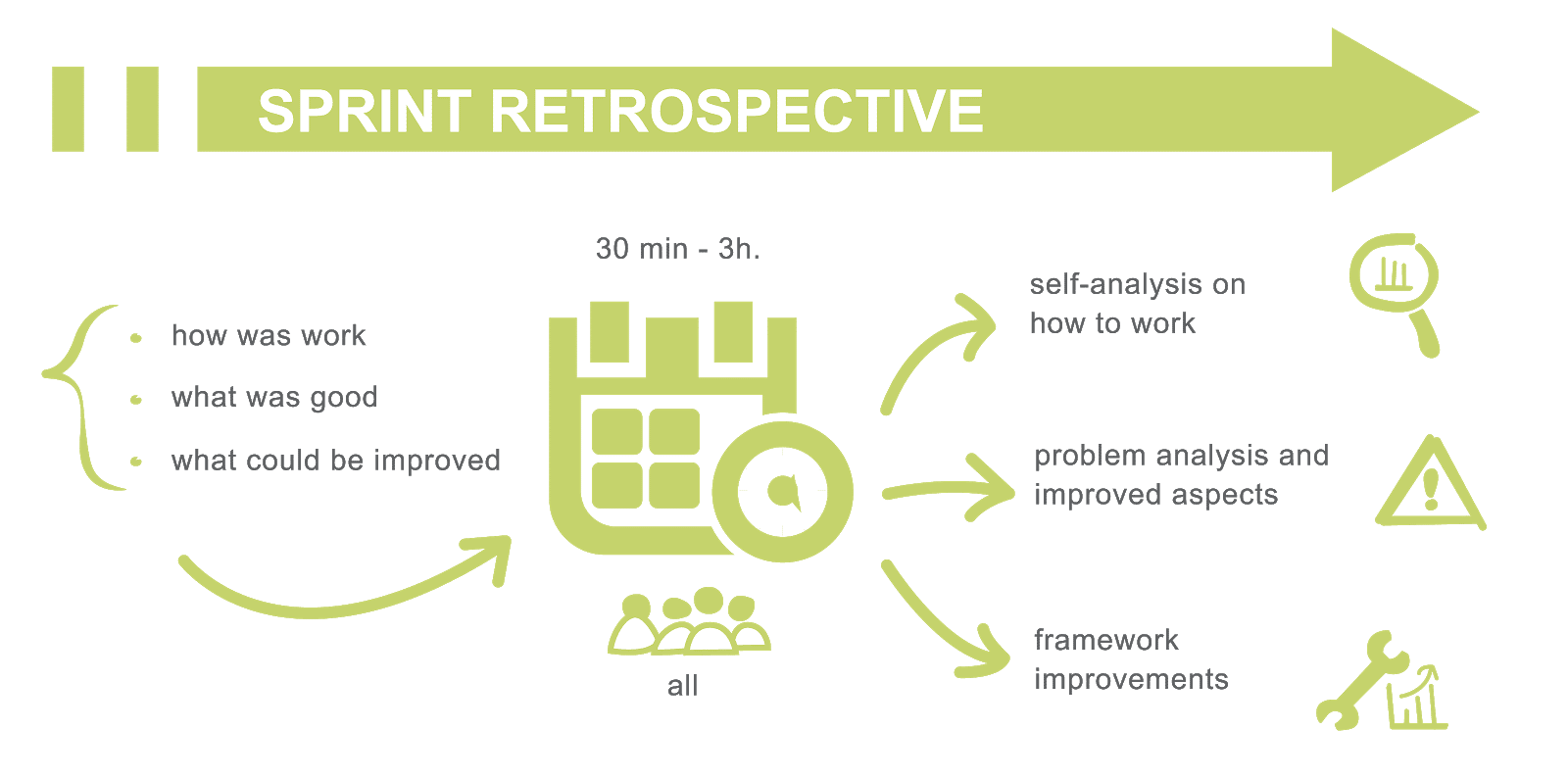
Developers want autonomy and flow. XP and Scrum use a retrospective to find out what is preventing the team from finding that flow. If you create the conditions for a successful retrospective, developers will tell you exactly what the issues are.
Two conditions that can help a retrospective be successful are having a good facilitator and a safe environment. Consider having someone from outside your team run retrospectives. If this isn't possible, ensure that the facilitator has the variety of tools they need to set the team at ease and help them share their experiences. To ensure a safe environment, the facilitator can perform a safety check with the team. If the scores are low, a good facilitator would try to address the causes of this insecurity. Facilitators should also consider displaying the Prime Directive, which states, "Regardless of what we discover, we understand and truly believe that everyone did the best job they could given what they knew at the time, their skills and abilities, the resources available, and the situation at hand."
A good retrospective allows team members to articulate their issues and blow off steam. This can improve team morale while also allowing the team to identify areas for improvement and ensure that those improvements are implemented. The team should reflect on what went well and what did not and then identify and agree on ways to improve. At least one item should be identified as an improvement and be brought into the next sprint as a work item. It's critical to follow through with these to improve team velocity. If articulated issues aren't being addressed, members will stop sharing. Retrospective tasks should be stored and tracked in Jira, Asana, or your favorite work management tool, and Scrum Masters or managers should be held accountable for delivering improvements to process and environment.
2. Use Source Control for Everything
The Joel Test turns 20 years old in August 2020. The first question on The Joel Test is "Do you use source control?" That's no longer controversial: source control tools and services like GitHub, GitLab, and Bitbucket are free and ubiquitous, and responsible developers use source control on their projects.
Still, it's less common to see source control used in the rest of your organization, but the tools that allow your Scrum team to deliver working software to production also need source control. Not doing so risks change failures and gumption-killing productivity traps.
That Bash script that someone threw together on your Jenkins server? It might grow into a much larger tool. Storing that tool in Git from the very start allows people to see how it's changed over its lifetime and what has been reverted. Those release scripts that Bob wrote two years ago before he went overseas? What if they are lost when the temporary build servers lose a disc and there is no backup because development data isn't archived? When everyone has access to the moving parts of your system, velocity is improved.
3. Generate Realistic Test Data
Real-world data is messy: encoding issues from the characters in place names like São Paulo or Malmö, user-generated content playing fast and loose with standards, and malicious input, like XKCD's famous "Little Bobby Tables".
To avoid errors in production, bring the test data to the developer. The sooner a codebase is exposed to production data, the sooner these issues can be flushed out. It's worthwhile to have an Azure DevOps or Jenkins job to generate and cleanse a subset of production data for developers to fetch daily or weekly. It's important to comply with privacy legislation, like the GDPR, regarding Personally Identifiable Information (PII) and anonymize the data so individuals can't be identified. Another important consideration is data that belongs to other organizations. It would be convenient to have all the credit history of your banking customer's clients on developer machines, but the bank's Compliance department would likely take a dim view.
Your development team will appreciate having recent production quality data. This allows them to validate changes and gain confidence in getting code to production faster, which improves velocity.
4. Setup a CI/CD Pipelines
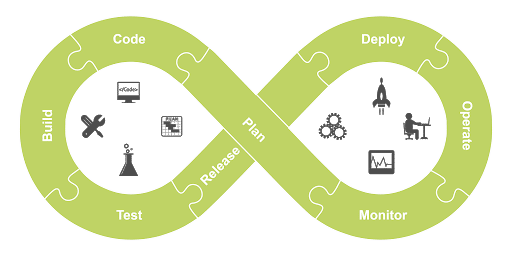
CI/CD pipeline flow
Releases to production used to be out-of-hours rituals where teams ate pizza and ran manual tasks to move a new release onto production servers. Errors or mistakes needed to be diagnosed and rectified by tired team members. That same team would need to prove that the changes had been successful for some time after the release. Now we see continuous integration and continuous delivery (CI/CD) pipelines delivering code to production several times a day, and teams hopefully eat more vegetables.
Implementing a CI/CD pipeline can automate the multiple steps involved in a code release. In addition, releasing in smaller increments more often lowers risk and shifts compilation and testing as far left as possible. Incorporating a suite of automated tests into the pipeline and bundling with error monitoring at each stage can provide early feedback to developers. This improves velocity by giving them confidence in their changes and avoiding integration pain between branches.
5. Use Error Monitoring and Response Tools

Your application errors can speak to you if you have the tools to listen. An error monitoring tool like Rollbar can provide insights into errors throughout your SDLC. Error monitoring improves team velocity by providing a virtual safety net for your developers: knowing that a release candidate made its way through your pipeline stages with no extra errors allows your developers to deploy smaller changes more often with greater confidence, which enables higher throughput of changes to production.
As new code is deployed in each environment, error monitoring tools can alert developers immediately to issues. This early insight helps reduce the cost of change and increases developer confidence since they know they will be the first to see the issues. Error monitoring metrics also provide key triage data such as how many customers are experiencing the error and on what platforms or browsers. This can help team members quickly understand and prioritize a problem.
The work of managing errors can be automated through an error monitoring tool by raising issues directly in Jira or another issue tracker, or sending Slack notifications. A good error monitoring tool will then provide contextual data for debugging. For example, Rollbar offers a single interface for data such as HTTP request parameter values, local variable values, platforms, browsers, users, telemetry, and deep linking into source code repositories.
Error monitoring can improve developer confidence and speed up error resolution, increasing your development team's velocity.
Conclusion
Velocity is the heartbeat of your team's delivery. Tracking velocity allows your team to deliver features and improvements more predictably, and incrementally improve the speed of delivery. Consistent velocity scores allow you to reliably estimate what you can deliver in the next sprint and therefore please your stakeholders by delivering the changes you committed to deliver. Velocity scores over time are an important diagnostic tool for the health of your team.
This article has shared five powerful tools that high-performing IT organizations use to improve the performance and happiness of their development teams. Which one could you implement in the next sprint?