
Tools like Rollbar have changed the way development teams are recording and managing their exceptions. What used to be a very personal developer-by-developer activity can now be a team-wide tool for greater transparency, and increased application quality.
But many still treat exception monitoring as a developer activity, and they are not leveraging its benefits across all environments, from development to stage and integration, to systems testing and production. Let's review why exception monitoring in all environments is so beneficial, and some best practices for setting it up.
By standardizing with Rollbar for exception monitoring across environments and clients, you have better visibility and better input into the application and development processes, and it’s a good way to ensure quality prior to delivering releases to customers.
But even after release, the tool has been extremely useful for:
1. Support of CD and canary releases:
More and more we are asked to consider using continuous delivery (CD) and canary release processes.
While in many cases it is not possible or a good fit, when we do get an opportunity to implement CD,
exception monitoring is the only way to support it, because code goes from developer to source repo
and directly to prod as long as the basic tests show up green. We know very little about the code,
and do not have the eyeballs on exceptions that we normally would. This way, an exception in prod is
just one more trigger to let us know that a release should be rolled back. We do the same for our
server monitoring, so of course we should as well with code. We also use it to help with more
supporting data in A/B testing of releases.
2. Ensuring environment parity:
We do our best to ensure parity between all environments, but it’s simply not possible. Different
applications have different requirements in terms of infrastructure. Our development environment is
primarily static, and it is local. Production can be on different configurations, and even different
clouds. So we are dealing with a hybrid scenario where for each client the production environment is
unique. These variables can easily cause issues where the differences in the production environment
compared to dev causes issues in code—things such as a mismatch on frameworks and other artifacts.
When this happens, sometimes exception monitoring is the only way to know.
3. Key Performance Indicator - accountability all the way to production:
I believe that all developers have increasing responsibility for what happens in production. But in
our case, because we own the development processes of our clients, there is no question our
developers are accountable for code quality all the way up to production. And the analytics we
receive from Rollbar help us gauge how well our Dev groups are doing with code quality, where it
matters the most—the user. This allows us to quantify the impact directly and leave no question as
to how what happens in Dev impacts users.
4. Provides details about exceptions:
If there is a bug in production, often QA, Support and Ops teams are left with little information to
pass on to the Dev team. In reality, what usually happens is that it is not reported at all, not
until the error is noticed in earlier environments much later on. With Rollbar we are able to show
details about exceptions. Even if Support, QA and Ops do not understand the details, they are able
to communicate more effectively with developers and get them pointed in the right direction faster.
It helps avoid the “worked on my machine” problem, and helps relate application issues with
potential infrastructure issues. Plus, it reduces the amount of time that it takes for issues to be
resolved. And because we have monitoring of all environments, we can see if the exception was
already showing up in earlier environments. (If so, something is broken in our process.)
5. Helps QA and Ops communicate with developers:
Using the People data feature in Rollbar, we can, via support or email, engage directly with
customers, before they potentially submit a ticket, or even worse, reach out on social media about
the issue they encountered. This is a tailored user experience, and something that only happens in
production.
6. Web Jobs:
We do a lot of web jobs that run specific serverless functions. In Azure, we use
WebJobs,
Azure Functions and
AWS Lambda. Because these scripts are not a part of our applications
and our applications’ error reporting, it is not easy to know what is going on, or to debug them. In
both AWS and Azure when a script breaks, sometimes the only indicator you get is that the job stops,
or it perpetually restarts. Calls to Rollbar in our exception blocks in some cases is the only way
of knowing if something breaks. When we use Rollbar in our web jobs, we make sure that the web job
is set up as its own environment so we can report on each one.
We do get exceptions and errors in production, even for small applications. See below:
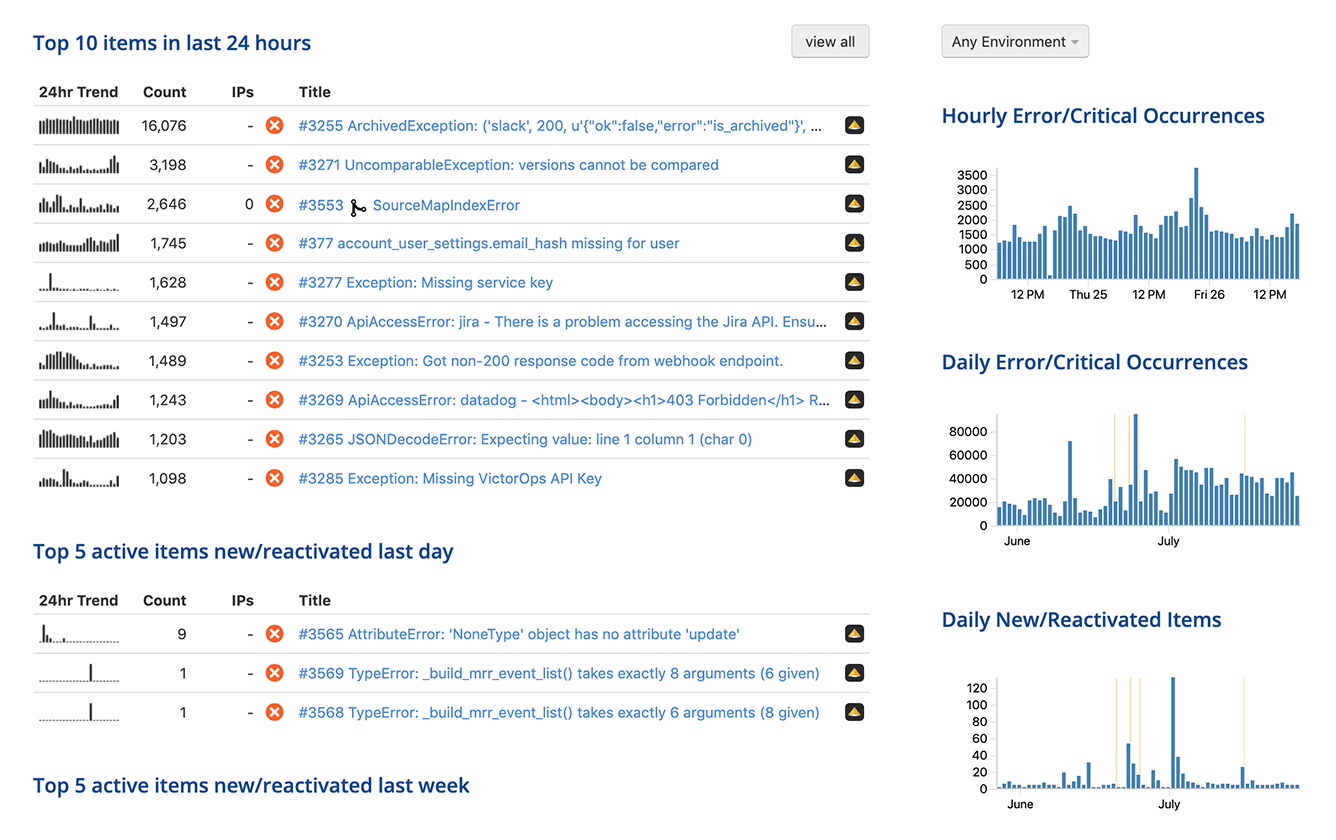
As long as that is happening, we need exception monitoring in production because as we move from the
development environment to production, the cost of each exception goes up. The consistency across
all environments means that our knowledge does not drop off a cliff, and we have greater
transparency, consistency, and quality of product.