
I'm excited to share a fun and insightful interview our friends at The Changelog recently did with Paul Biggar, Founder at CircleCI (and Rollbar super-user). We're big supporters and fans of The Changelog and we asked their host and master interviewer Adam, to help us produce a few short interviews with our customers. It's a fun project that lets us pull back the curtain and learn more about how our customers monitor their applications and processes for handling errors and deploying code. Enjoy!
{: .highlightbox}
Featured in this interview: Adam Stacoviak, Founder & Chief Editor at The Changelog, a podcast on software development and open source. Subscribe via iTunes or RSS. Paul Biggar, Founder of CircleCI, a leading continuous integration platform.
Adam: Hey there. Adam here, editor-in-chief of Changelog. I'm here with Paul Biggar, founder of CircleCI (circleci.com) and we're gonna talk about how important Rollbar is to him and his team to help them deliver on their brand promise to ship better coder faster. Paul, tell me about CircleCI. What types of services do you provide?
Paul: CircleCI is a continuous integration and continuous delivery platform. Our customers are the developers in an organization. Developers rely on us heavily as part of their deployment workflows.
Adam: I guess deploying obviously is important. You've got the phrase 'ship it' for a reason, so it's a critical piece to an ops or developer organization to be able to ship code fast, ship code reliably.
Paul: Right. The idea is to do continuous delivery, where you're constantly delivering value to your customers. Every time a developer pushes code, the CircleCI test will run and they'll validate that that code works, whether it's on a branch or whether it's on the master branch, and then they deploy the code to Heroku, to AWS, to wherever your hosting is.
Adam: Break down the problem a little bit deeper for those out there who might not be that informed about CI or CD services and what the value is that you actually do. Some people might still be rsync-ing or doing different things to deploy their code, and they don't have workflows and things like that. Can you break down the problem a little bit more, and how CI and CD solves that?
Paul: You can always just run tests on your own machine, and you can always just deploy from your own machine. It's hard to really describe how much better it is for it to be part of an automated, continuous process, but it's like night and day. When our customers switch to a continuous delivery model from deploying on their machine whenever, it completely changes the velocity of their team and of their organization. If you're doing continuous delivery, you literally change how your company delivers code and the speed at which it delivers code. I would never work at a company that didn't do continuous delivery.
If you're doing continuous delivery, you literally change how your company delivers code and the speed at which it delivers code.
Adam: So clearly you're like a part of the machine that should not/could not break. If you break, you're losing trust, you're losing value, and ultimately you're not delivering your brand promise. So tracking errors, tracking bugs, keeping your team informed about breaks, keeping your team informed in terms of like - it might even be different parts of the service, but you have a microservice architecture versus a monolith, and you've got various teams plugging into CircleCI and how things are built... Let's talk about the obvious question here, which is how do you use Rollbar? And not just how do you use Rollbar, but why do you use Rollbar?
Paul: I was talking about doing continuous delivery there, and one of the key parts about doing continuous delivery, you don't just have to test your software, but you have to constantly keep track of it. If you're going to be doing deploys ten times a day or twenty times a day, and you have to know that each deploy works, and the way to do that is to have really good production monitoring. Rollbar is the thing that you need to do that monitoring. You need to make sure that every time you deploy, you're gonna get an alert if something goes wrong, and that's exactly what Rollbar does for CircleCI, for our infrastructure.
If you're going to be doing deploys ten times a day or twenty times a day, and you have to know that each deploy works, and the way to do that is to have really good production monitoring.
Rollbar is the thing that you need to do that monitoring.
Adam: Let's talk about what you did before Rollbar. Before Rollbar, I'm sure your team had processes for monitoring, tracking, fixing errors... Help me understand what it was like for your team before Rollbar. What kind of processes did you have, how did you deal with these things prior to introducing Rollbar to your team?
Paul: Before we used Rollbar we used a different crash reporting service and we were shopping for a new one. We did the tour and looked at Rollbar and all of its competitors, and it was really the feature set of Rollbar that was super impressive and that made us go there, in particular the people tracking I think is really... It's not just a great feature, but it also kind of speaks our language because we're very focused on making sure that the customers are happy and we want to make sure that we have an individual understanding of what happens to each customer. The fact that we're able to click on "This customer is experiencing a lot of errors", and to be able to follow the progression of errors that they've been experiencing is very valuable to our team.
The fact that we're able to click on "This customer is experiencing a lot of errors", and to be able to follow the progression of errors that they've been experiencing is very valuable to our team.
Paul: If we get an e-mail from a customer and the customer says, "Your website keeps glitching on me," and being able to go to Rollbar and to say, "Okay, this individual customer, this is how they're experiencing the site"... Because otherwise you have to give an overall state of things, and overall things are looking good, because if they weren't, we'd be dealing with it.
[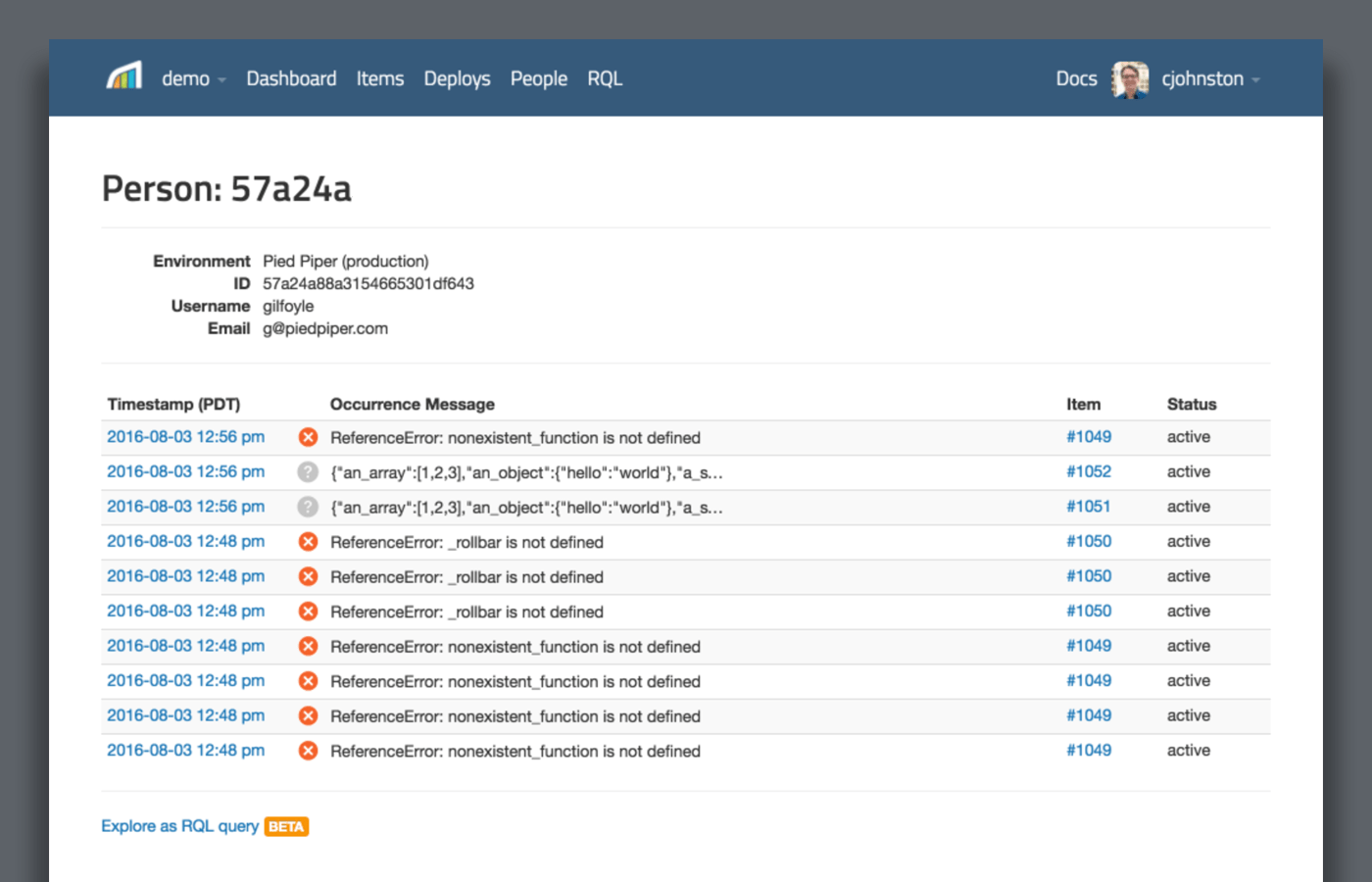](/features/)
{: .imgcaption}
Person Tracking as seen in Rollbar
Adam: I think Rollbar to me, just in general error monitoring, seems to be engineer-focused, but I've gotta imagine, based on what you've just said there, that it supports whomever is doing support for you; maybe it's actually engineers who do support for you. Can you talk a bit about that crossover, where it's an informing tool not just to engineers, but also to other parts of the business?
Paul: Everyone at CircleCI is empowered to look into whatever they need to look into. If you're in support, and our support people are engineers - have an engineering background, they will often need to dive into what exactly a customer is experiencing, so being able to see... We use a couple of monitoring tools, we also use Datadog, so being able to see there's an increase in errors on Rollbar, there's a decrease in reliability on the API - you would see that in Datadog - this is stuff that you need to be able to say, "Why is the customer experiencing this problem?". Rollbar is really used by the dev-ops and the engineering team, but it's an invaluable tool for the support team too.
Rollbar is really used by the dev-ops and the engineering team, but it's an invaluable tool for the support team too.
Paul: And when we were first looking at why is Rollbar gonna be valuable, it was a time when we didn't have a support team. All of us were doing support; we were either alternating by day or by week at that point, and it was part of the tool set. It was just a great place to start looking at where a customer experienced a certain problem, and that was what won Rollbar over for us.
Adam: It's obvious that with those kinds of insights and that kind of informing across teams - not just engineers, but other parts of the business - you've gotta be able to make customers happy pretty quickly. Can you give me any particular experience where something was happening, an error was happening, and you were able to track down who it was affecting? Maybe you found that before they even reported it to the support, and you won the day, you won a customer for life.
Paul: I think it's a lot more mundane than not, and I think intentionally so. People don't tell dramatic stories about their monitoring software if their monitoring software is good. When Rollbar is working the way that you know it's working, it's because you don't have any dramatic situations. You get alerts about new things that are happening, we get it shipped into Slack, and if Rollbar is telling us that something is happening, we immediately look into it, and on the website and with the customers nothing happens; everything stays the same. We fix the bug, we figure out why it's happening. We either mute the alert or we fix it, and it doesn't get to the point where a customer has to be dramatically saved, or anything like that. The site just keeps working.
We fix the bug, we figure out why it's happening. We either mute the alert or we fix it, and it doesn't get to the point where a customer has to be dramatically saved, or anything like that. The site just keeps working.
[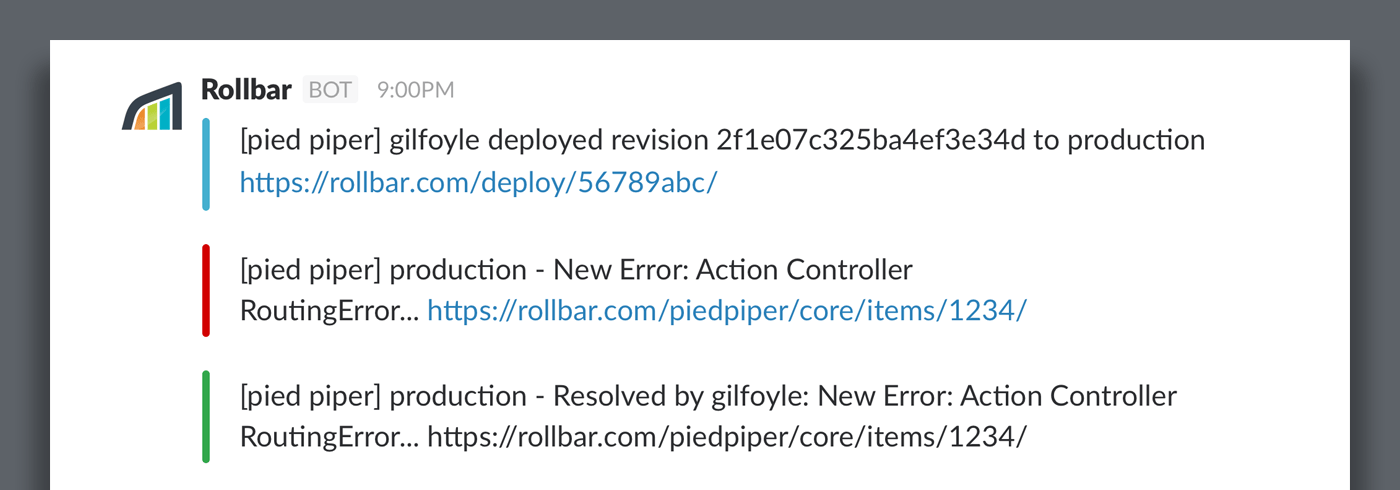](/features/)
{: .imgcaption}
Rollbar Notifications in Slack (Deploy, New Error, Resolved Error)
Adam: You talked before about your choice of Rollbar and their feature set. Can you give me an example - and you may have already done this, but can you give me an example of particular features that you were excited about, and which features they had that you dreamed about and were able to put in use? Can you walk me through what those were?
Paul: I think deploy tracking is probably not an intuitive feature, but it completely changes how you use it. Knowing which is the first deploy that introduced this problem allows you to immediately solve the problem. "This was first introduced at this commit" - then you go back to that commit, you look at the 20 to 50-line diff between that and the previous deploy, and you're like, "Oh, this is what we changed; this is what the exception looks like. It's obvious what the problem is."
Adam: How often does something like that happen for you?
Paul: All the time. When you're looking at monitoring, "How did it start happening?" is as close to a root cause analysis as you can get.
"How did it start happening?" is as close to a root cause analysis as you can get.
Adam: I'm just thinking, since it happens - let's not say all the time, because that sounds bad, let's just say often... And this is a feature that you sought out. Previously, this superpower was not available to you and your team; you signed up for Rollbar and suddenly just this single feature is a super power for you to help you catch things.
Paul: After we added deploy tracking on our end and during our deploy process something pings Rollbar, it completely changed how we were able to track down errors. Bugs and errors and exceptions and all that are just a constant. It's not like we deploy perfect software and it works all the time. We're constantly triaging, "Are these exceptions important enough to fix or are they just noise? Are they handled by the dev or is it just noise that comes from having a distributed system?" and the ability to say when that particular error started happening is just like a night and day feature. If you don't use that feature, once you have it you immediately realize how useful it is and how valuable it is. You can get to the root cause immediately.
After we added deploy tracking on our end and during our deploy process something pings Rollbar, it completely changed how we were able to track down errors.
[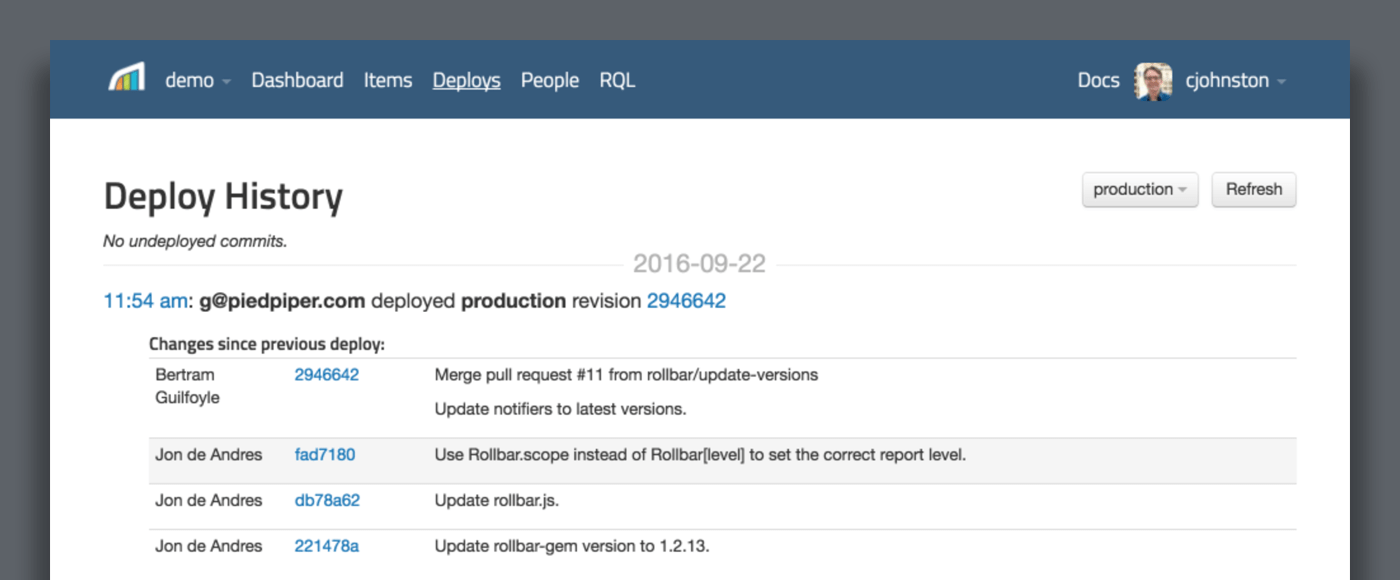](/features/)
{: .imgcaption}
Deploy Tracking as seen in Rollbar
Adam: Can you give me an example of another feature that you use that you're totally in love with that isn't very clear that it's available to you, that you use quite often?
Paul: The ability to configure when something alerts you. The gap between a hundred occurrences and a thousand occurrences of something is quite big. Being able to have Rollbar say "This thing just became a big deal" is important.
Adam: So you can basically say, "If this type of thing has happened before a hundred times, that's okay. We're familiar with that, we're aware of that bug, we're on that bug, our team is tracking that bug." But when it blows up to a thousand or two thousand, clearly it's gone from dwarf to monster.
Paul: Right, because it's very rare to suddenly have a new bug that we've never seen before. What usually happens is the bug will happen in a very rare situation. Maybe someone triaged it at some point and said, "That's low down the list of priorities," and then all of a sudden, a bug that we've seen dozens of times, hundreds of times before, once-a-day sort of thing, suddenly we an error a thousand times in an hour, or ten thousand times in an hour. That's when something becomes super serious, and that's the things that we want to get alerted about.
suddenly we see an error a thousand times in an hour, or ten thousand times in an hour. That's when something becomes super serious, and that's the things that we want to get alerted about.
Adam: The brand promise of CircleCI is "Ship better code faster", which in my opinion - and maybe the listeners will feel this way, too - seems pretty confident. You're confident in what you do, you're confident in what your software promises to deliver to its customers. Can you talk a bit about how Rollbar has helped you deliver on that brand promise?
Paul: The most important thing in delivering things quickly to your customers is having a level of confidence that the code works. You can't perfectly test something before it goes out, you can't perfectly validate it. You're gonna put it in front of the customers and something weird and new is gonna happen, and you have to know when that goes wrong. You have to have something like Rollbar to tell you something just went wrong and to alert you about it immediately. Otherwise you would just be paralyzed by fear. You'd be unable to ship anything because you wouldn't know when it would go wrong and what the downsides would be.
You can't perfectly test something before it goes out, you can't perfectly validate it. You're gonna put it in front of the customers and something weird and new is gonna happen, and you have to know when that goes wrong.
Adam: Let's assume anyone who listened to this is someone who needs to use Rollbar. Someone needs to know about this tool, needs to know about this product, needs to know how it has changed how you do business because of it. I'd like them to know how important this tool is to you. A better question might even be, "Could you have done what you're doing with CircleCI, the level of morale for the team, the happiness level - all these different things that play into this, without Rollbar's help?"
Paul: We operate at serious scale, and the first thing we do when we create a new service is we install Rollbar. We need to have that visibility, and without that visibility it would be impossible to run at the scale we do. Certainly with the number of people that we have. We're a relatively small team operating a major service, and without the visibility that Rollbar gives us into our exceptions it just wouldn't be possible. If there's people out there who ship code without Rollbar, I can only imagine the pain that they're going through.
the first thing we do when we create a new service is we install Rollbar. We need to have that visibility, and without that visibility it would be impossible to run at the scale we do.
If there are people out there who ship code without Rollbar, I can only imagine the pain that they're going through.
Adam: That's awesome. Thank you so much for your time today, Paul. I really appreciate you taking the time to speak with me. For those tuning in, if you haven't yet, head to rollbar.com to learn more. Cheers!
Thank you to Paul and the team at CircleCI for sharing this level of insight and for leading by example when it comes to continuous delivery and working to maintain error-free experiences for their users. Bravo!
If you haven’t already, sign up for a 14-day free trial of Rollbar and let us help you
take control of your application errors.